はじめに
概要
![]() 鼻歌を歌って UTAU に音符を入力できる、UTAU 用プラグインです。
鼻歌を歌って UTAU に音符を入力できる、UTAU 用プラグインです。
「た〜たたた♪」というように歌詞をすべて「た」にして歌ったものを WAVE ファイルに録音しておき、その WAVE ファイルを解析することにより、歌の音長・音程を UTAU に自動入力します。
鼻歌採譜プラグインは、WAVE トレース方式の自動調声プラグイン「うたりす」が過去に搭載していた「採譜モード」を強化・独立させたものです。うたりすと関連が深いので、「うたりすファミリー」という位置づけになっています。
インストール
ダウンロードしたアーカイブ(zip ファイル)を UTAU のウィンドウにドラッグ&ドロップすると、鼻歌採譜プラグインがインストールされます。
使い方
鼻歌採譜プラグインを使う際は、
- 鼻歌を「た」で歌って WAVE ファイルに録音
- UTAU のテンポを設定
- 鼻歌採譜プラグインを起動
鼻歌採譜プラグインの紹介動画(http://www.nicovideo.jp/watch/sm19721079)でも使い方を解説していますので、参考にして下さい。
鼻歌の録音
鼻歌採譜プラグインが対応している WAVE ファイル形式は以下のようになっていますので、鼻歌を録音する際は、以下の設定にして下さい。
| サンプリング周波数 | 44.1kHz |
|---|---|
| チャンネル数 | モノラル(推奨)/ステレオ |
| 量子化ビット数 | 16 ビット(推奨)/8 ビット |
| フォーマット | リニア PCM |
全て「た」だと早口の部分を歌うのが難しいと思いますが、その場合は「ら」を混ぜてもある程度大丈夫です。「たたらたったた〜♪」みたいな感じです。
一応、「た」以外でも、はっきりとした子音なら採譜できることになっています。母音(あいうえお)はダメです。母音に近いと思われる「な行」「ま行」「ん」もダメだと思います。
鼻歌を歌う際は、感情は込めずに、できるだけ正確な音程で歌うように心がけて下さい。イヤホンで原曲などを聴きながら録音すると、音程やテンポが取りやすくなるでしょう。
録音の際は、歌唱のみをソロで録音し(コーラス等は入れない)、歌唱以外のノイズがなるべく入らないように注意して下さい。
WAVE の先頭と末尾にはノイズが乗りやすい(録音ボタンを押した音等)ので注意して下さい。SoundEngine 等で先頭・末尾のノイズ部分を切り捨てることをオススメします。
音量の正規化(ノーマライズ)は不要です。
ちなみに、私は、リニア PCM 録音できる IC レコーダー、オリンパス DS-800 で歌唱を録音し、PC に転送しています。モノラル録音推奨とかいいつつ、自分はステレオ録音ですが(笑)。他に、マイクデバイスとして使える Microsoft の「Xbox 360 Wireless Headset WH01」(型番は推定)も持っていますが、ノイズが多く、録音しようとすると常にレベルメーターがかなり振れている感じなので、使っていません。
UTAU のテンポ設定
UTAU を起動し、UTAU のテンポを設定します。
鼻歌採譜プラグインは、UTAU のテンポ設定を基準にして音長の解析を行うので、テンポは正確に設定して下さい。
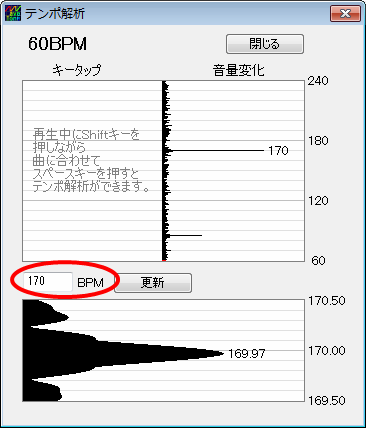 既存の WAVE ファイルのテンポを測定するには、WaveTone が便利です。
既存の WAVE ファイルのテンポを測定するには、WaveTone が便利です。
WaveTone を起動し、テンポを測定したい WAVE ファイルをドラッグ&ドロップします。ドラッグ&ドロップ時に表示されるダイアログの設定は適当で構いませんので、「解析」ボタンをクリックします。
解析が終了したら、[解析→テンポ解析]メニューをクリックすると、解析結果が表示されます。下の方に表示されている BPM がテンポです。一番上に表示されている BPM は違うので注意して下さい。
鼻歌採譜プラグインを起動
テンポの設定を終えたら、鼻歌採譜プラグインを起動します。予め UTAU に音符を入力しておく必要はありません。まっさらな状態で、鼻歌採譜プラグインを起動して下さい。
鼻歌採譜プラグイン画面上で設定を行い、スタートボタンをクリックして下さい。採譜結果が UTAU データに反映されます。
以下で、鼻歌採譜プラグインの画面について説明していきます。項目名の上にマウスカーソルを合わせると、簡単なヘルプが表示されます。
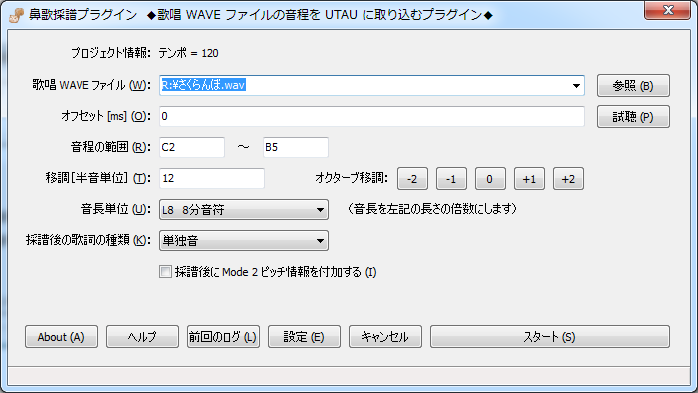
歌唱 WAVE ファイル
先ほど鼻歌を録音した WAVE ファイルのファイル名を、フルパスで入力します。WAVE ファイルをドラッグ&ドロップすると簡単です。
オフセット
オフセットを入れると、WAVE ファイルの先頭を削る(使わない)ことが出来ます。単位はミリ秒です。例えば、録音の際、録音ボタンを押してから 2 秒間歌わない状態があったのなら、オフセットに「2000」を指定します。
あまり使う場面は無いとは思いますが、オフセットにマイナス値を入れることもできます。マイナス値を入れた場合は、先頭に空白を付加します。
「試聴」ボタンをクリックすると、オフセットでの削られ具合を確認することが出来ます。
音程の範囲
自分の歌唱の音程がどの範囲にあるのかを指定します。音程の表記方法は UTAU と同じで、例えば中央のドであれば C4、半音上がると C#4 というような表記になります。半角で入力して下さい。
うたりすの場合とは異なり、この範囲をあまり狭める必要はないかもしれません。デフォルト設定くらい広めに取ってもたぶん大丈夫だと思います。
なお、この「音程の範囲」は、次の「移調」の値に関係なく、「自分の歌唱そのもの」の音程で指定して下さい。
移調
解析した音程を UTAU データに変換する際、移調することが出来ます。移調量は半音単位で、プラスなら上に、マイナスなら下に移調します。通常は 0 にしておけば大丈夫です。
原曲よりも 1 オクターブ「低く」歌った場合は、そのままだと 1 オクターブ「低い」UTAU データができあがってしまいます。この場合は、移調を「12」と指定し、1 オクターブ「持ち上げて」やることで、元の音程で UTAU データを入力することができます。
音長単位
UTAU に入力する音符の長さを、ここで指定した長さの倍数にします。
例えば「8 分音符」を指定すると、UTAU には、8 分音符、4 分音符、付点 4 分音符、2 分音符……が入力されます。
採譜したい曲に使われている音符の長さの「半分の長さ」を指定すると良い結果になります。原曲の最短音符が 8 分音符の場合は、16 分音符を指定します。
採譜後の歌詞の種類
歌詞を単独音(た)で入れるか、連続音(a た)で入れるかを指定します。
採譜後に Mode 2 ピッチを付加する
通常、採譜結果は音符情報のみとなりますが、このオプションを有効にすると、鼻歌のピッチ曲線が入るようになります。
ピッチ曲線が入ると、採譜(音程)の意味が無くなりますので、あくまでも参考用です。通常はオフにしておく方がいいでしょう。
データ提供
今後の鼻歌採譜プラグイン開発の参考にさせていただきたく、データ提供にご協力いただければ幸いです。
うまく採譜できるケース、数音間違えるケース、全く採譜できないケース、いろいろあるかと思います。どのような歌唱 WAVE だとどのように採譜できるか、を知りたいです。
データ提供にご協力頂ける場合は、
- 歌唱 WAVE
- ↑の歌唱 WAVE を採譜した際のログファイル(プラグインフォルダにある SaiLis.log)
鼻歌採譜プラグインを再度起動して「前回のログ」ボタンをクリックすると、前回のログファイルの内容が表示されますので、その内容をメールにコピペして、アップローダには WAVE ファイルのみ、という形でも構いません。
送り先メールアドレスはこちらを参照下さい。
WAVE ファイルはメールでは送らないで下さい。
技術解説
「どのような仕組みで採譜をしているのか?」というのが気になる方もいらっしゃるかもしれませんので、解説してみます。興味のない方はこの章を読み飛ばして下さい。
採譜処理は、音量解析、音長解析、音程解析、クオンタイズ処理を順に行っていきます。次節以降でそれぞれについて解説します。
音量解析
音量解析は、下準備のようなもので、音量解析自体では、特段何もしません。WAVE ファイルの各地点での音量を、単純に 0〜1 の間で記録しておきます。便利のため、最大値が 1 になるように正規化を行っておきます。
音長解析 STAGE 1:音符の区切りの検出
音長解析は STAGE 1 と STAGE 2 の 2 段階からなります。STAGE 1 では、「どこが音符の区切りとなりえるか」を検出します。
音符の区切りの検出では、MFCC(メル周波数ケプストラム)という指標を用います。理論をきちんと理解していませんが、MFCC の差分二乗和が一定値以下なら音声が定常状態にあり、逆に、一定値以上なら音声は非定常状態にある、という区別ができます。音声が定常状態にあるというのはつまり母音ということで、逆に、子音→母音への流れが非定常的、ということになります。つまり、MFCC の差分二乗和が一定値以上の地点が、子音の先頭ということです。
「た〜たたた」で歌っている場合、子音の先頭で音符を区切れば良いので、MFCC の差分二乗和が一定値以上の地点で音符を区切ります。
ところで、音長解析を行う手法として、音量を元に解析する、という方法も考えられます。MFCC 差分二乗和を元に解析する方法と、どちらが良いのでしょうか。
「た」の先頭では音量がほぼゼロになるので、「音量がゼロから急激に上がる部分を音符の区切りとする」という解析が行えそうです。
しかし、「た」以外の歌詞、例えば「ら」で歌った場合、音量で解析するのは困難になります。「ら」の先頭では音量はゼロにならないからです。この点、MFCC 差分二乗和では、ある程度の解析が可能です。
鼻歌採譜プラグインの使用法を説明する際は、検出精度を考慮して「た」で歌うことを推奨していますが、本音は、どんな歌詞でも検出できるようにしたいと思っています。従って、「た」以外も検出しやすそうな MFCC 差分二乗和の方が良いと判断しています。
また、歌唱者や音程によっては、ずっと発音していても一地点ごとに音量が上下する場合もあり、音量を元に解析するとこのようなケースにも対応できません。
音長解析 STAGE 2:検出した区切りの取捨選択
STAGE 1 で検出した音符の区切りをすべて採用すると、音符がとても細かくなってしまいます。STAGE 2 では、それぞれの区切りを区切りとして採用するかどうかを判断し、不要な区切りを破棄します。
まず、明らかに不要な区切りとして、発音をやめた地点が区切りとして検出されている場合は、それを破棄します。MFCC 差分二乗和は定常常態か非定常状態かを表す指標なので、発音している状態→無音に変化した場合も、一定値以上になってしまうことがあり、STAGE 1 では区切りとして検出されています。この場合、音量を見て、発音→無音(下がりエッジ)なのかどうかを判断し、そうであれば破棄します。
次に、音長単位(鼻歌採譜プラグイン起動時にユーザーが設定した値)ごとに WAVE を区切ってみて、他の区切りに包含されてしまう区切りを破棄します。区切りが近接している場合、最初の区切りを採用すると、そこから音長単位の間は区切れませんので、次の区切りは破棄することになります。逆に、2 番目の区切りを採用することにした場合は、最初の区切りは採用できません。
どちらの区切りを採用するかは、MFCC 差分二乗和と音量の積を計算し、値が大きくなるほうの区切りを採用することにしています。その理由は、MFCC 差分二乗和が大きいほど明確な区切りであることと、発音している間は音量が大きいことから、両方を考慮して尤度を求めたかったからです。
以上により、区切りが定まりますので、区切りを先頭として、音長単位の間を音長とします。区切りと区切りの間が長い場合は、音長単位の倍数で出来る限り長くなるように音長を定めます。
音長解析の図解
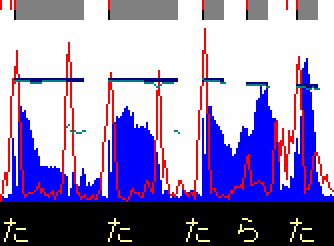 音長解析の内容を視覚化したのが右の図です。
音長解析の内容を視覚化したのが右の図です。
「た、た、たらた♪」と歌った時の波形データ(振幅)を、青い棒グラフが表しています。赤い折れ線グラフが MFCC 差分二乗和です。上部の灰色が、音長の解析結果です。真ん中あたりの黒いのは無視して下さい。
MFCC 差分二乗和の折れ線を見てみると、発音開始時に折れ線がピークになっているのが分かります。「ら」の時はピークが低いですが、なんとか拾えています。
折れ線のピークのうち、下がりエッジを除いたものが、上部の灰色の左側にある赤い線です。最後の「た」のすぐ左側にも赤い線がありますね。赤い線の間隔が音長単位より狭いので、どちらかしか採用できません。ピークの大きさや、音量の大きさを見て、左側ではなく右側のピークを採用しています。
音程解析
音程解析では、まず、各音符の全地点で音程を求めます。
全地点で同じ音程であれば、その音符の音程が決定しますが、通常、そういうことはありません。
たとえば、ド→レ→ミと上昇している時の「レ」の音符の音程は、先頭のほうではドに近く、末尾のほうではミに近いでしょう。また、ビブラートがかかっていると、レとミを行ったり来たりしているかもしれません。音程の揺れをある程度吸収したうえで、「レ」と判定する必要があります。
揺れを吸収するために、2 種類の重み付け判定をしています。
1 つには、音符の両端の音程よりも、中心部の音程を優先します。音符の両端は、前後の音符の音程に引きずられやすいため、その音符の正しい音程を反映していない可能性が高いのです。
もう 1 つは、音量の大きい部分の音程を優先します。歌唱者の自信がある部分は音量も大きくなりそうな感じがするからです。でもこれは微妙かもしれませんが。
上記 2 つの重み付けを考慮したうえで、音符全体でどの音程がもっとも多いかを見ます。「ド」の地点が 10 地点、「レ」が 50 地点、「ミ」が 20 地点なら、「レ」の地点がもっとも多いので、その音符を「レ」と判断します。
音程は通常、半音単位で判定しますが、上位が接戦の場合は、セント単位(半音の 1/100)で判定して、最終結果を半音単位に丸めています。
クオンタイズ
音符の区切りがユーザー設定のクオンタイズとずれている場合は、ユーザー設定に合わせて音符を移動します。
移動は単純に、もっとも近いクオンタイズ地点に移動させているだけです。
以上で、採譜が完了します。
コラム:MFCC について
音長解析に用いている MFCC(メル周波数ケプストラム)についてですが、私の理解の範囲で、MFCC って何ぞや、ってのを書いてみます。それ違う! とかありましたら教えてください。
 音声の時間領域での波形(つまりは WAVE データ)をフーリエ変換すると、音声の周波数領域での波形(つまりスペクトラム)を得ることが出来ます。スペアナで見る、低音が大きいとか、高音が小さいとか、ってやつですね。
音声の時間領域での波形(つまりは WAVE データ)をフーリエ変換すると、音声の周波数領域での波形(つまりスペクトラム)を得ることが出来ます。スペアナで見る、低音が大きいとか、高音が小さいとか、ってやつですね。
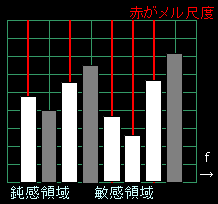 スペクトラムの横軸はリニア(マス目が均等)なわけですが、これを、人間の聴覚特性に応じて伸び縮みさせます。人間が敏感に区別できる周波数帯のマス目は細かく区切り、人間があまり感知しない周波数帯のマス目は大雑把に区切ります。この横軸の区切り方をメル尺度と言います。
スペクトラムの横軸はリニア(マス目が均等)なわけですが、これを、人間の聴覚特性に応じて伸び縮みさせます。人間が敏感に区別できる周波数帯のマス目は細かく区切り、人間があまり感知しない周波数帯のマス目は大雑把に区切ります。この横軸の区切り方をメル尺度と言います。
次に、メル尺度上で均等に、スペクトラムのサンプルを 20 個取ります。メル尺度上でサンプルをとる(灰色のサンプルを捨てて、白いサンプルを取る)ことにより、人間が敏感な周波数帯のサンプルを多く取ることができます。20 個というのは、音声認識の業界で使われる経験上の個数です。
取得した 20 個のスペクトラムの絶対値の対数に対して、さらにフーリエ変換(定義上フーリエ変換ですが、実用上はフーリエ逆変換でもいいらしい?)します。スペクトラムのスペクトラム、ということになりますが、これをケプストラムと呼びます。メル尺度上でスペクトラムのサンプルを取ったので、単なるケプストラムではなく、メル周波数ケプストラム(MFCC)と呼ばれます。なお、ケプストラムの尺度は再び時間になるのですが、元の時間とは意味合いが異なるようです。
MFCC (の低次側)から 12 個サンプルを取ると、音韻(つまり歌詞)の特定に役立つ数値が得られます。誰が歌っているかに関わらず、「あ」なら「あ」、「い」なら「い」で、12 個それぞれの値がだいたい同じになるようです。なお、12 個というのもやはり、音声認識の業界で用いられる経験的な個数です。
さてここで、ある時刻(たとえば 0.0 秒時点)と、そのちょっと後の時刻(0.1 秒時点)での MFCC を考えます。「あ〜〜〜(aaaaaaa)」と伸ばして歌っていた場合、0.0 秒でも 0.1 秒でも「あ」ですので、MFCC の 12 個の値はあまり変化しません。したがって、0.1 秒時点での MFCC の値と 0.0 秒時点での MFCC の値の差を求めると、ほとんどゼロになります。
一方で、「た〜〜〜」と歌った場合、「taaaaaaa」となりますので、0.0 秒は「t」、0.1 秒では「あ」となり、MFCC の 12 個の値が大きく変化します。よって、MFCC の差分がかなり大きくなります。
単なる差分よりも、差分二乗和の方が、差異が大きく出ますので、これにより、差分二乗和が大きければ、子音の先頭であると、判定できます。
以上が私の理解です。
お願い
ニコニコ動画
鼻歌採譜プラグインを使った動画をニコニコ動画に投稿したら、
- sm23708407(鼻歌採譜プラグイン 簡易説明書動画)
カンパ
Amazon でお買い物をする際は、こちらのリンクにあるサーチボックスから商品を検索して頂きますと、収益の一部がカンパとして還元されます。
頂いたカンパは、鼻歌採譜プラグインなどを開発するための資金に充当させて頂きます。
その他
データベース
| 種類別 | フリーソフトウェア |
|---|---|
| 名称 | UTAU プラグイン |
| ソフトウェア名 | 鼻歌採譜プラグイン |
| 紹介動画 | http://www.nicovideo.jp/watch/sm19721079 |
| 簡易説明書動画 | http://www.nicovideo.jp/watch/sm23708407 |
| ダウンロード | http://www2u.biglobe.ne.jp/~shinta/soft/SaiLis_JPN.html#Download |
| サポート情報 | http://www2u.biglobe.ne.jp/~shinta/soft/SaiLis_JPN.html#Support |
| バージョン | Ver 2.2 |
| 対応 OS | Windows 7 以降 |
| 対応 UTAU バージョン | Ver 0.2 系 / 0.4 系両対応 |
| ライセンス | クリエイティブ・コモンズ・ライセンス(表示 - 非営利 - 改変禁止 2.1 日本) ※営利目的で使用したい場合は事前にご相談下さい。 ※第三者から提供されている部分を除きます。第三者から提供されている部分については、元のライセンスに従います。 |
| 作者 | SHINTA |
| 作者 E メール | |
| 作者ホームページ | http://www2u.biglobe.ne.jp/~shinta/ |
| 製品番号 | SHWI-024-A |
改訂履歴
鼻歌採譜プラグインの改訂履歴は以下をご覧ください。
謝辞
鼻歌採譜プラグインは多くの方々のご支援に後押しされて、ここまで来ることが出来ました。ありがとうございます。
- 音声認識エンジン「Julius」を開発・公開して下さっているみなさん。
- 音声処理ライブラリ「ASAnalyzer」を公開して下さっているあっきーさん。
- うたりすのアイコン(鼻歌採譜プラグイン共用)を作成して下さったINAっちさん。
- 歌唱データを提供して下さったみなさん。
- 鼻歌採譜プラグイン紹介動画をご視聴下さったみなさま。
- 鼻歌採譜プラグインをご利用頂いているみなさま。
- 動画コメント等でご意見、ご感想を下さったみなさま。
- 日記、ブログ等で鼻歌採譜プラグインを取り上げて下さったみなさま。
- その他、関連する全ての方々。